Overview
Followong project is made under the rules of The University of Calcutta.Guided by Department of Statistics,Asutosh College
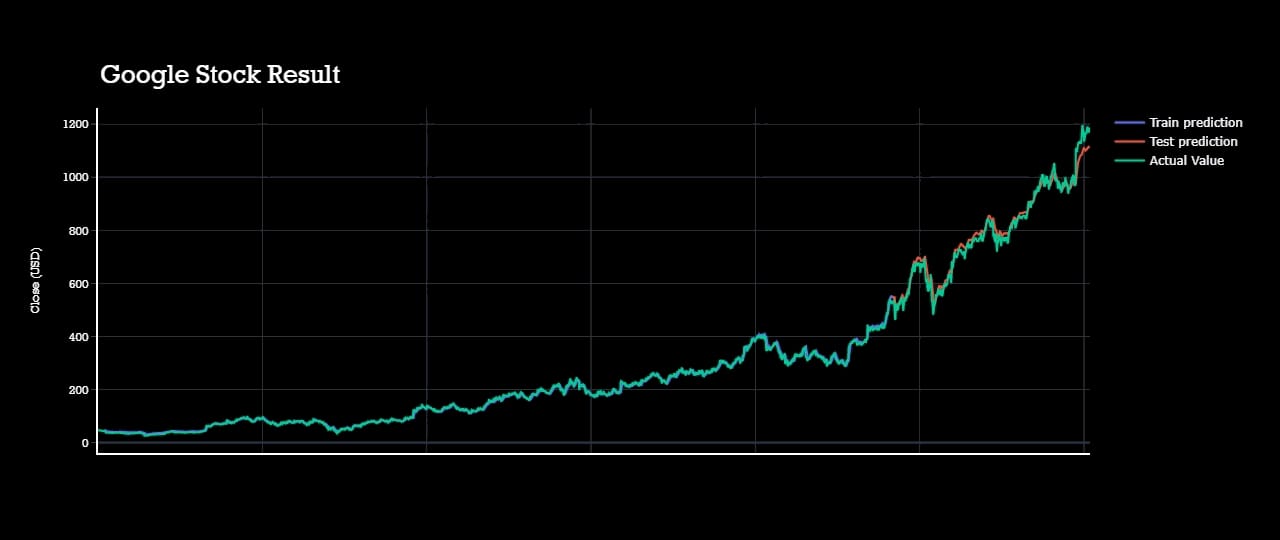
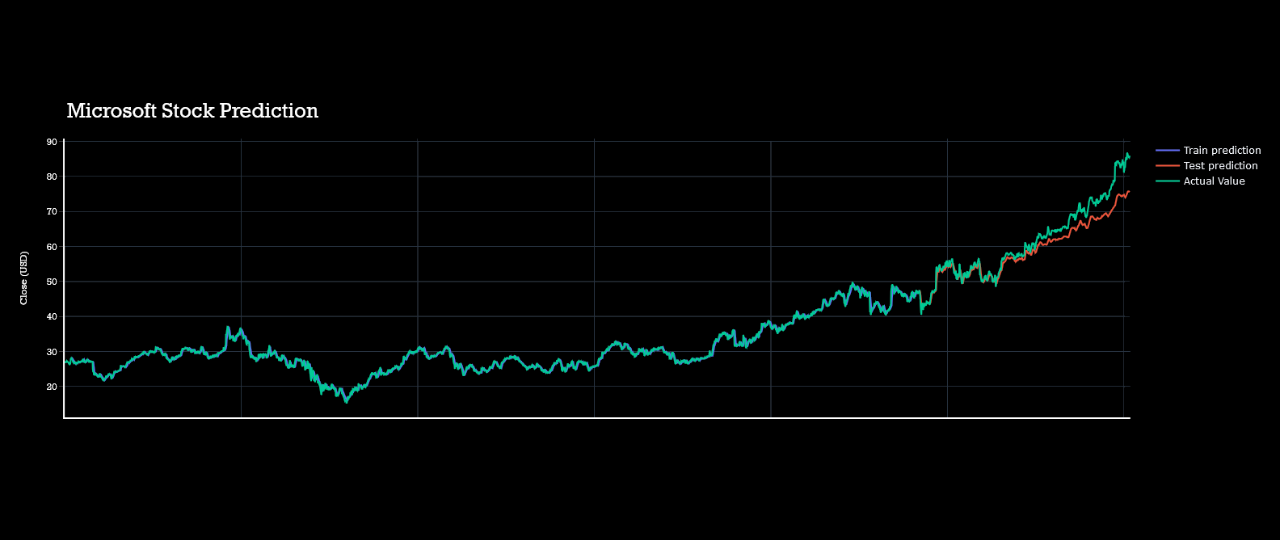
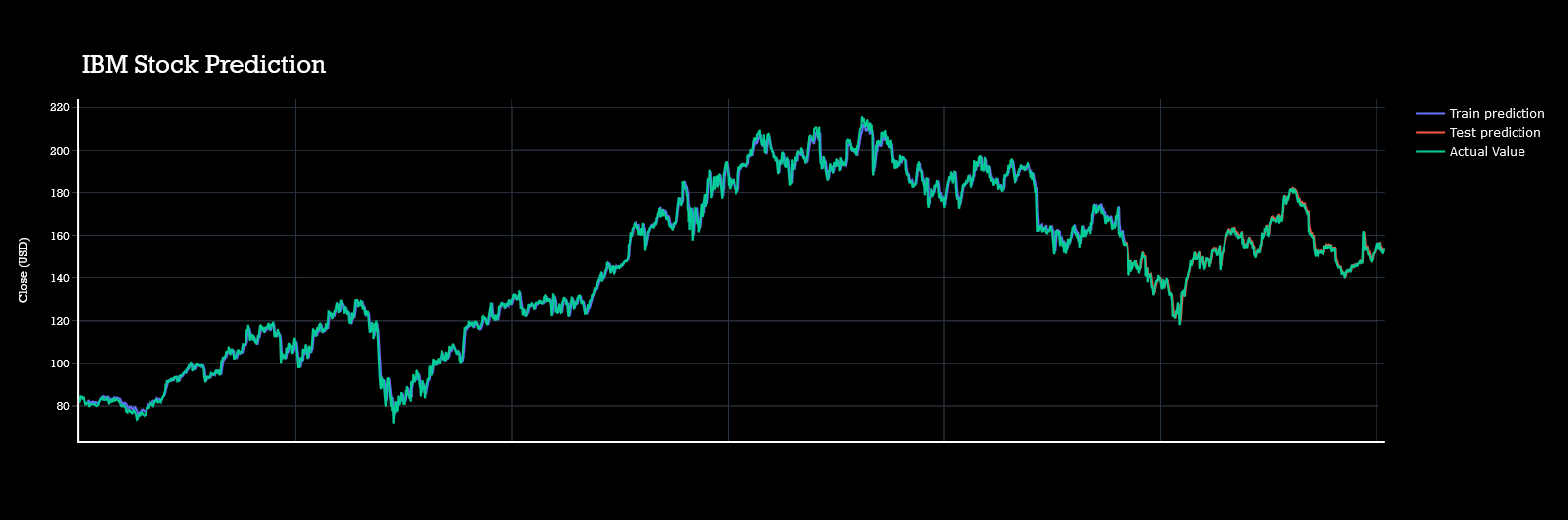
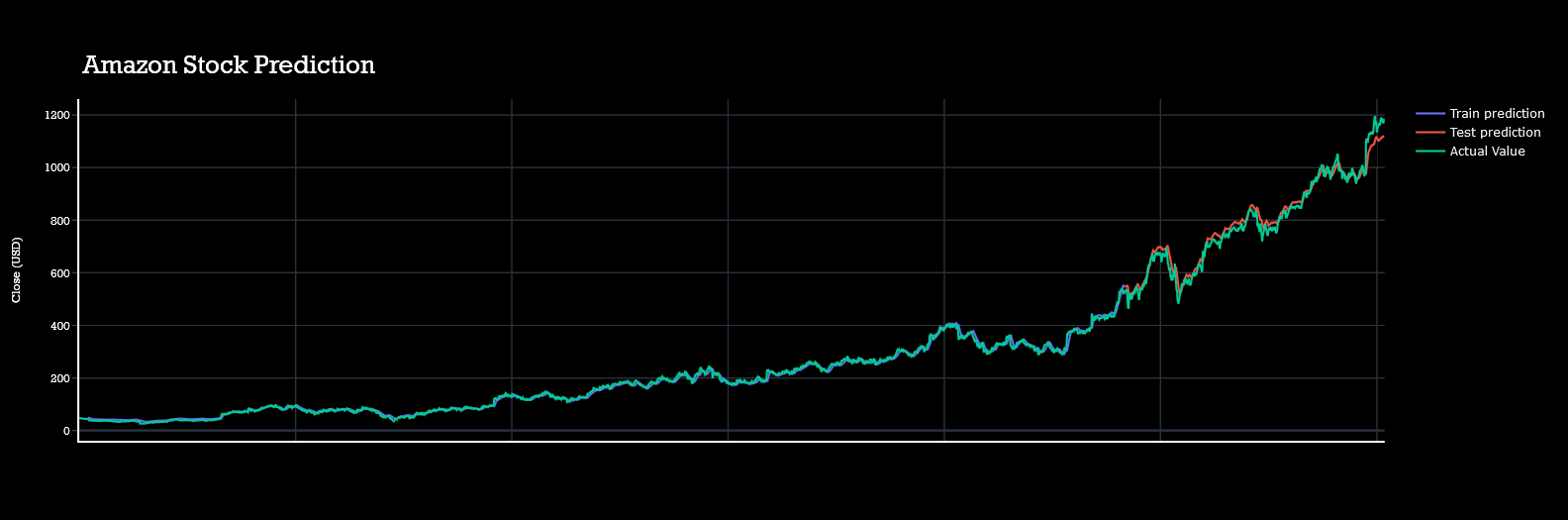
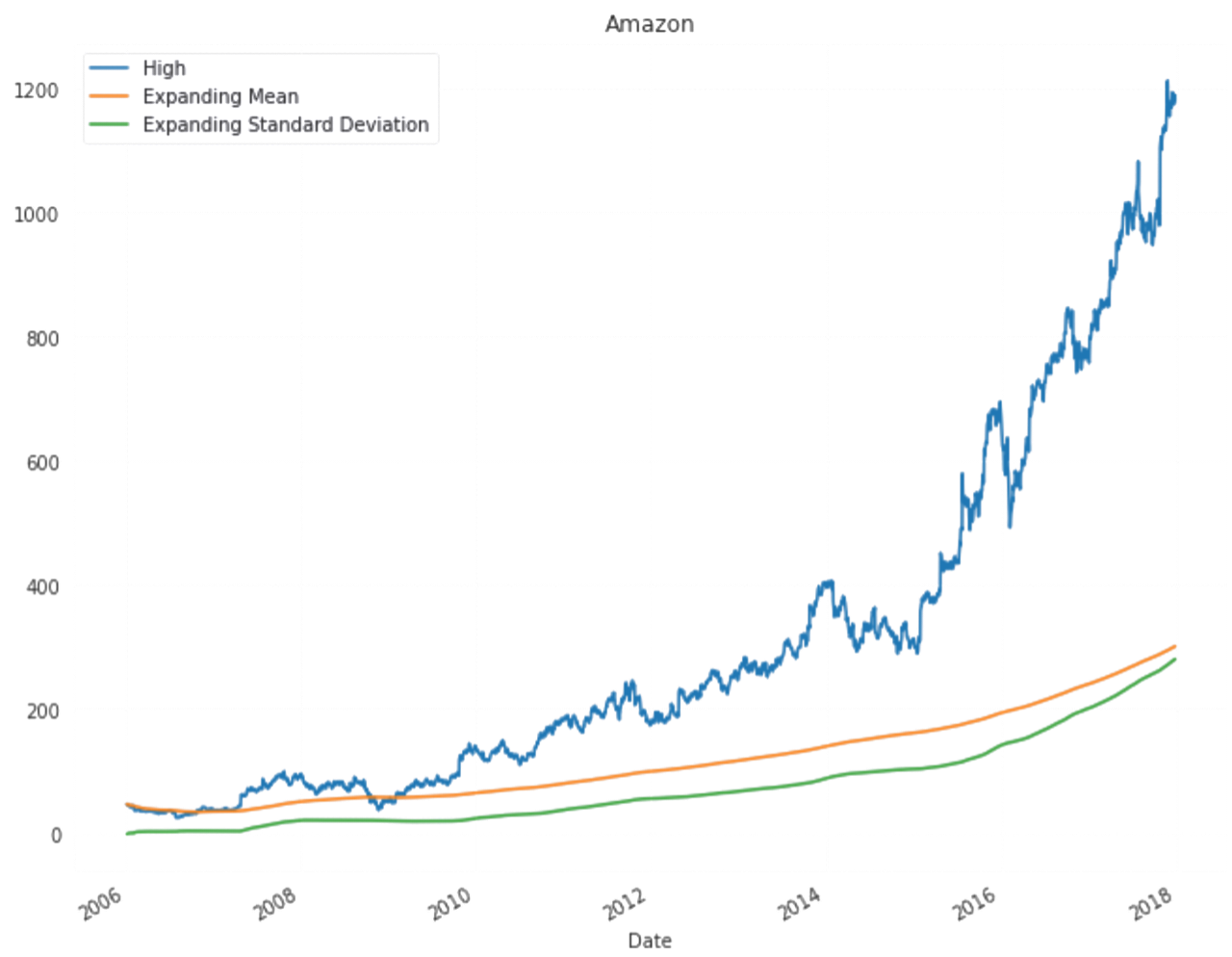
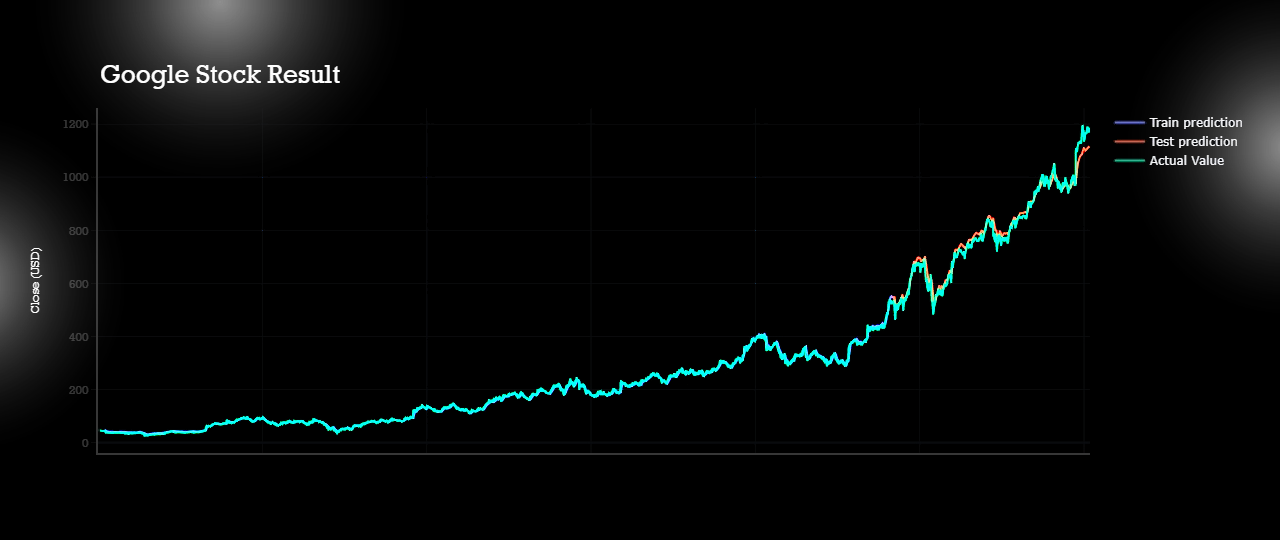
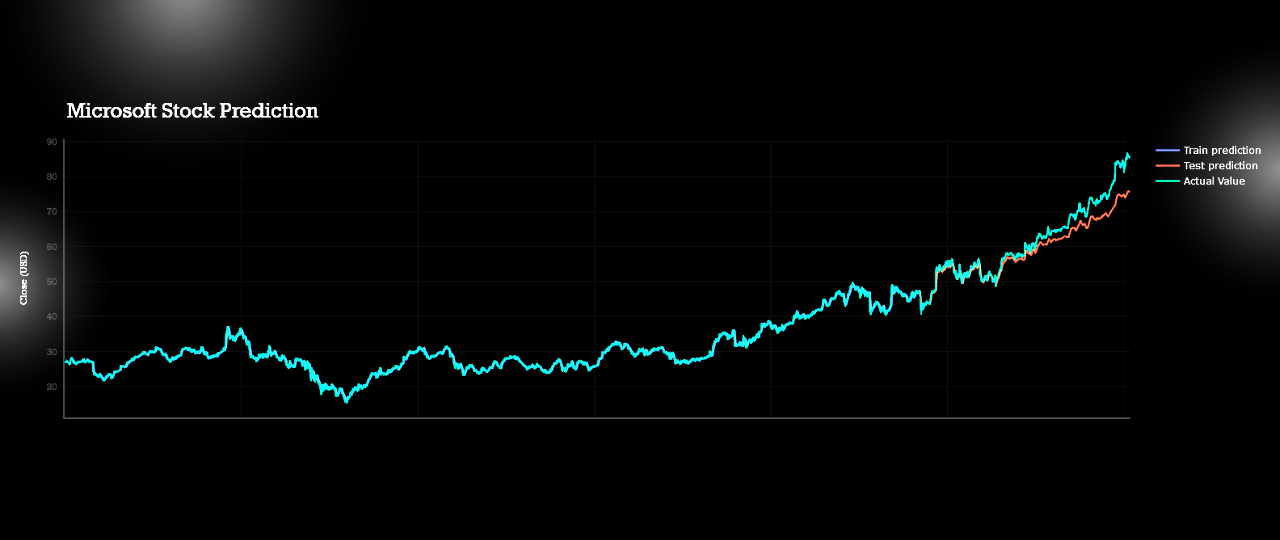
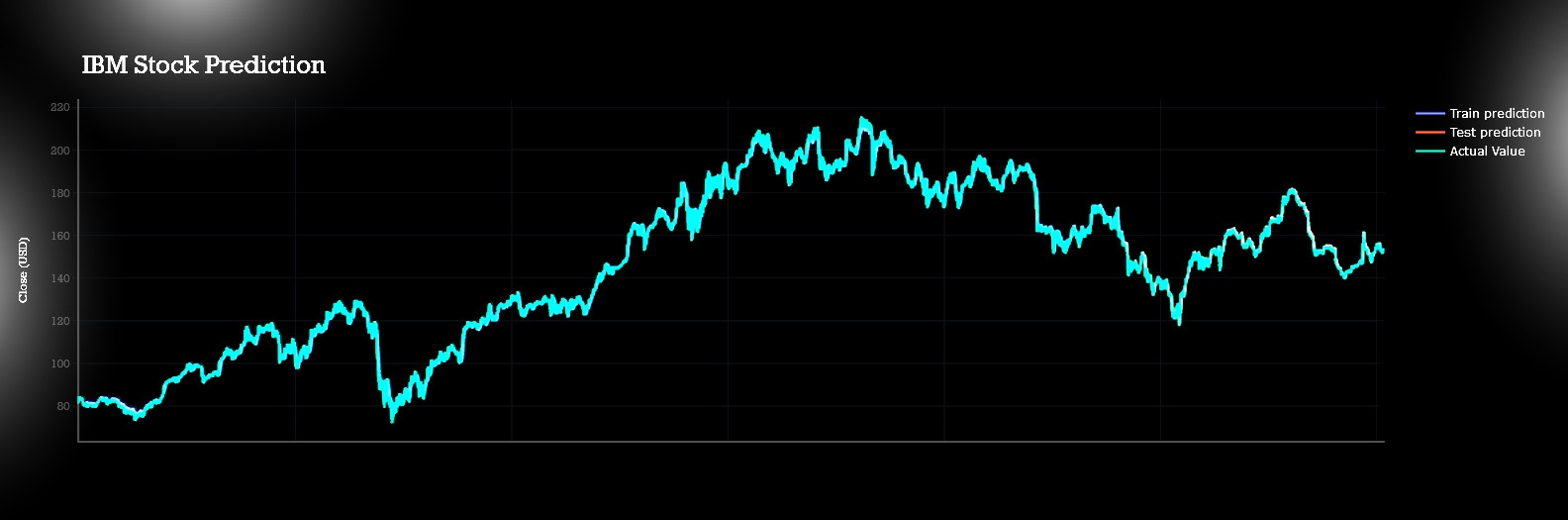
I had made htis page to demonstrate the whole process of forecasring live.Though it might not be so interactive but will be understandable clearly.
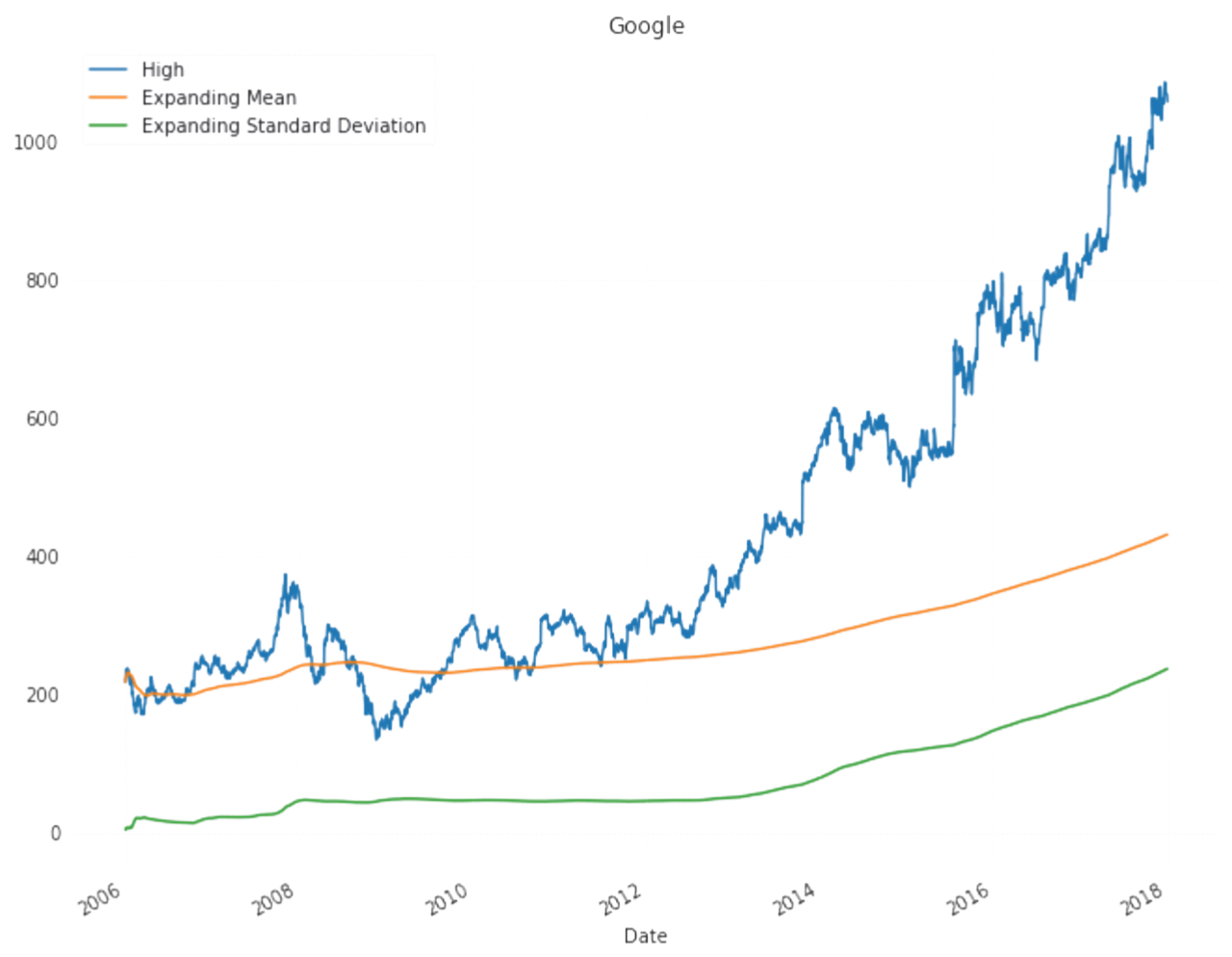
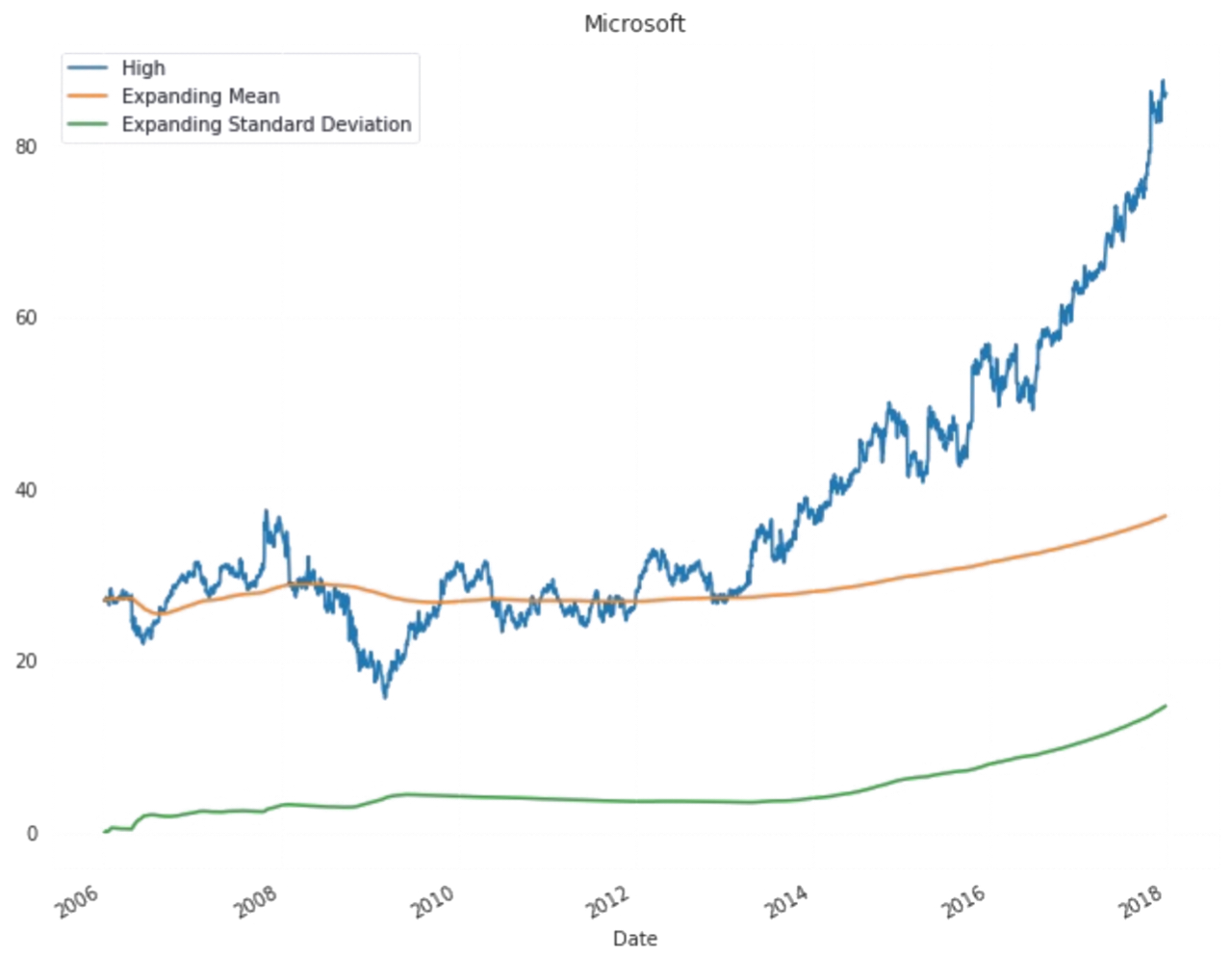
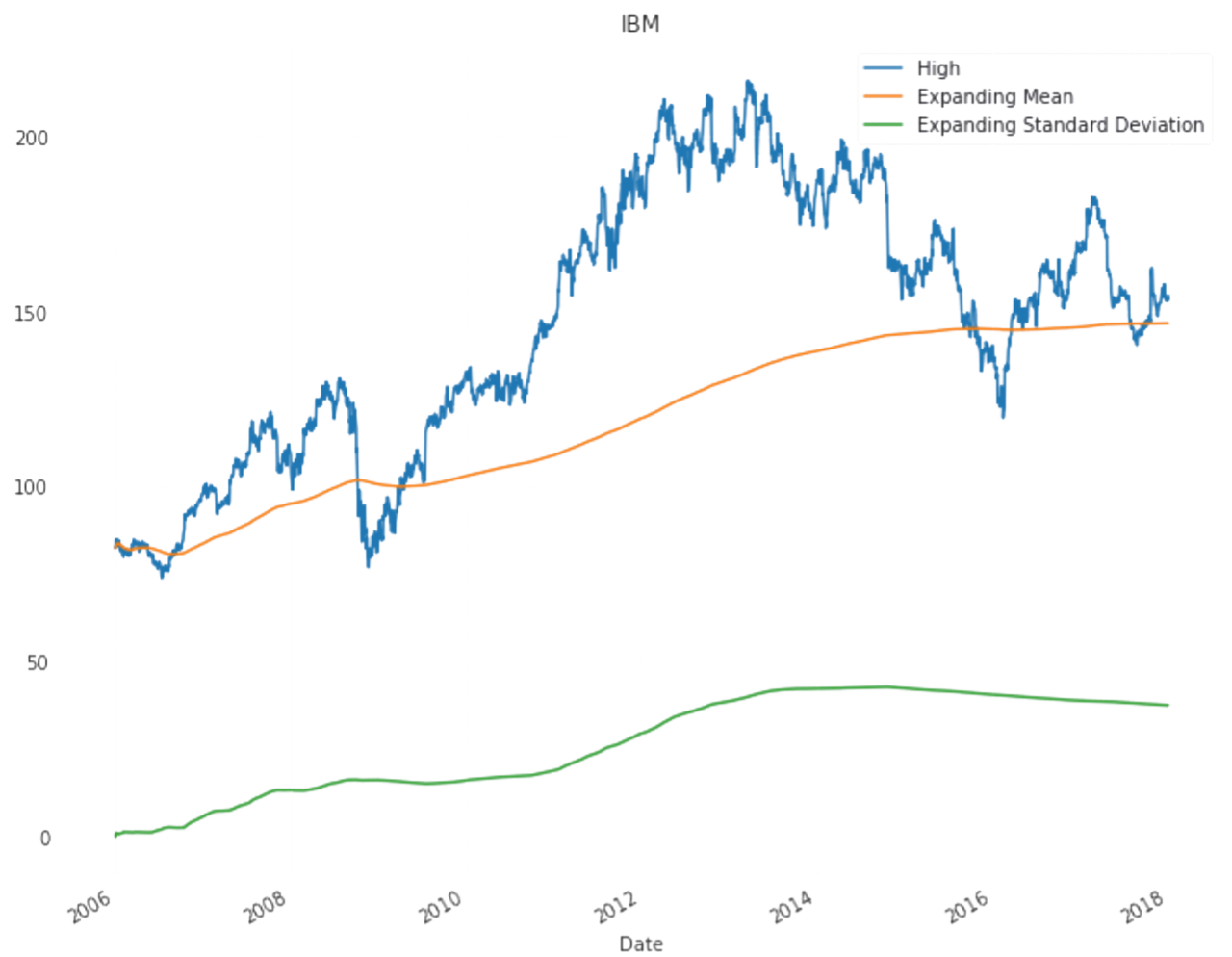
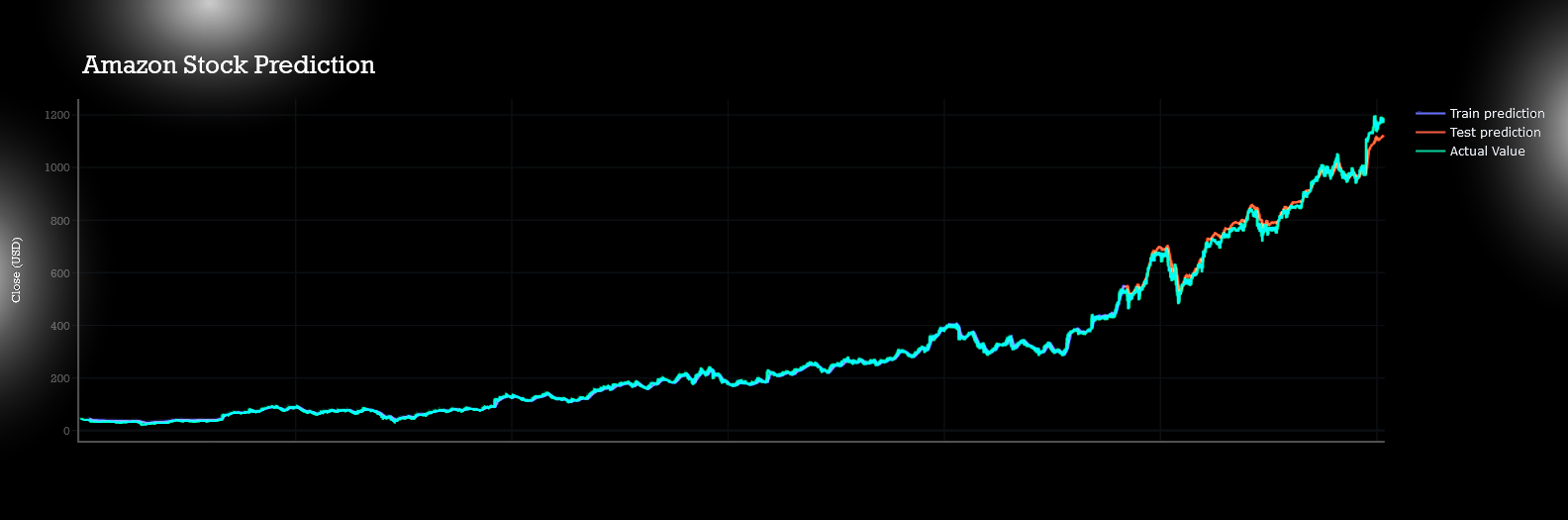
All predictions are done with almost with 80% acuuracy level.Actual data plot,test plot and train plots are almost coninsided to each other.